Machine Learning (ML)
1. What is Machine Learning?

Machine Learning (ML) is a branch of artificial intelligence (AI) that enables computers to learn from data and make decisions without explicit programming. Instead of following predefined instructions, ML algorithms identify patterns, improve their performance over time, and generate predictions based on input data. The ML process involves data collection, preprocessing, model training, testing, and deployment. Data is gathered from various sources, cleaned, and structured before being fed into an algorithm. The model learns patterns from training data, and its accuracy is evaluated using test data before being applied in real-world applications. Machine Learning is categorized into three main types: Supervised Learning, Unsupervised Learning, and Reinforcement Learning. Supervised Learning uses labeled data to predict outcomes, such as spam detection and fraud prevention. Unsupervised Learning identifies hidden patterns without labeled outputs, commonly used in customer segmentation and recommendation systems. Reinforcement Learning enables models to learn through trial and error, applied in self-driving cars and robotic automation. ML is widely used in healthcare, finance, e-commerce, and autonomous systems. It assists in disease diagnosis, fraud detection, personalized recommendations, and self-driving technology. Despite its benefits, challenges such as data bias, overfitting, high computational costs, and ethical concerns must be addressed for responsible AI development. As data availability and computational power continue to grow, ML will play a crucial role in shaping AI-driven applications, improving various aspects of human life and business operations.
Machine Learning continues to evolve with advancements in deep learning, neural networks, and big data analytics. Deep learning, a subset of ML, mimics the human brain using artificial neural networks to process vast amounts of data and recognize complex patterns. This technology is used in image recognition, speech processing, and autonomous robotics. Big data analytics enhances ML models by providing extensive datasets for more accurate predictions. The rise of cloud computing has also made ML more accessible by offering scalable resources for model training and deployment. However, ethical considerations remain a significant concern, especially regarding bias in AI algorithms, data privacy, and transparency in decision-making. Governments and organizations are working to establish regulations and frameworks to ensure ethical AI development. As research progresses, ML will continue transforming industries, improving automation, and driving innovations in various sectors. Its potential in revolutionizing technology, from smart assistants to advanced robotics, highlights its role in shaping the future of AI-driven applications and intelligent systems.
2. Supervised Learning
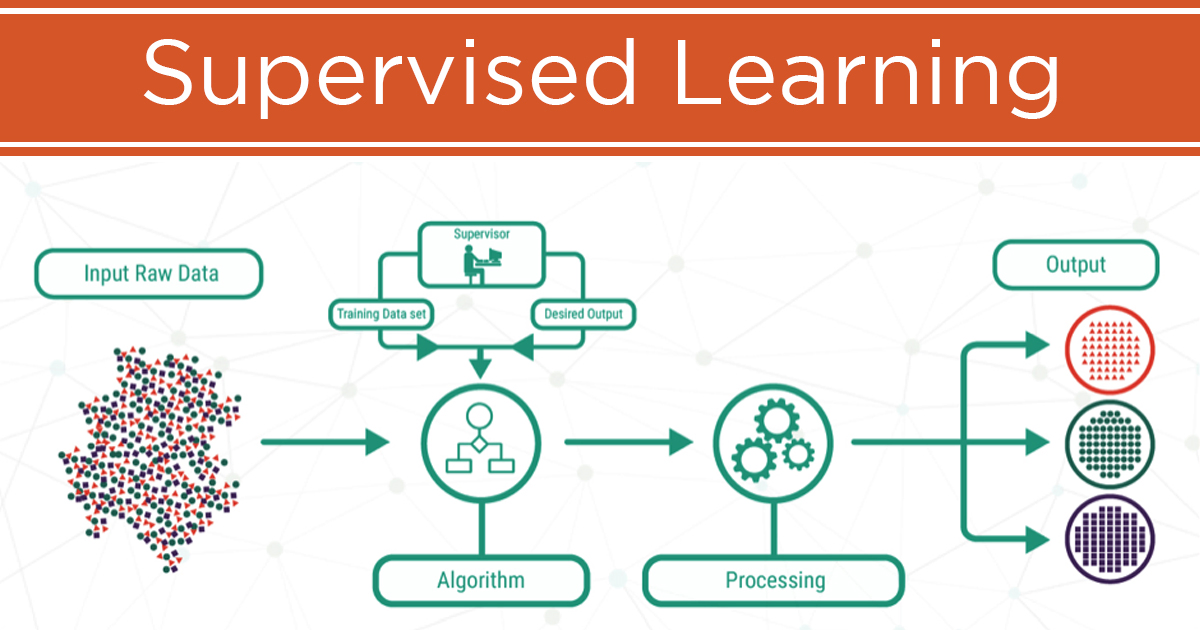
Supervised Learning is a type of Machine Learning where an algorithm learns from labeled data. In this approach, each training dataset consists of input features (X) and corresponding correct output labels (Y). The model analyzes this data and establishes a relationship between inputs and outputs, allowing it to make predictions on new, unseen data.
The process of Supervised Learning involves feeding historical data into the model, training it to recognize patterns, and evaluating its accuracy using test data. It is commonly used for classification (e.g., spam detection, fraud detection) and regression (e.g., predicting house prices, stock market trends). Popular algorithms used in Supervised Learning include Linear Regression, Logistic Regression, Decision Trees, Support Vector Machines (SVM), and Neural Networks.
This learning method is widely applied in various industries, including healthcare (disease diagnosis), finance (credit scoring), and e-commerce (recommendation systems). However, its effectiveness depends on the quality and quantity of labeled data. A major challenge is overfitting, where the model performs well on training data but poorly on new data. Despite these challenges, Supervised Learning remains one of the most widely used and effective approaches in Machine Learning.
3. Unsupervised Learning
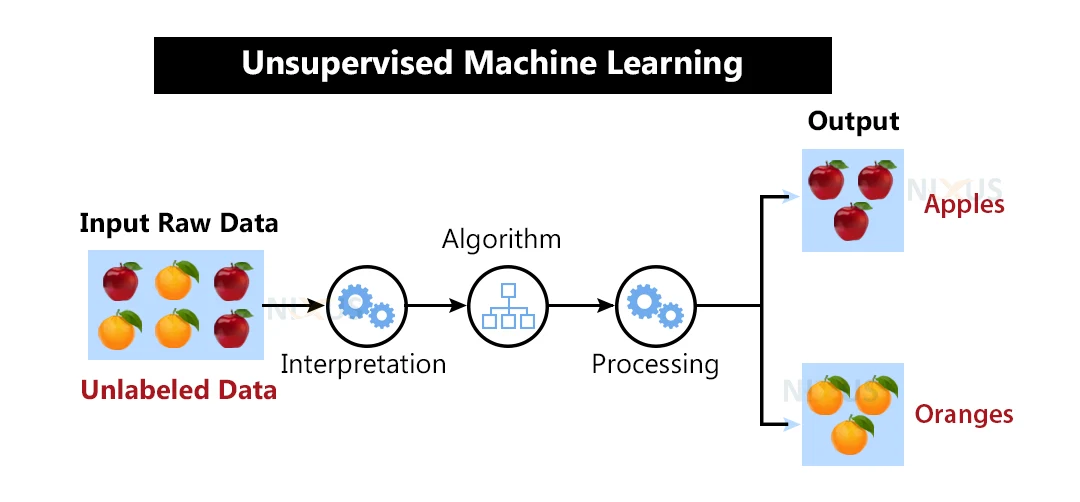
Unsupervised Learning is a type of Machine Learning where an algorithm learns from unlabeled data, meaning there are no predefined output labels. The model analyzes patterns, relationships, and structures within the data without any prior knowledge of correct answers. Instead of predicting specific outcomes, Unsupervised Learning helps in discovering hidden insights, grouping similar data points, and finding anomalies.
The two main types of Unsupervised Learning are Clustering and Association. Clustering groups similar data points together, such as customer segmentation in marketing (e.g., grouping customers based on purchasing behavior). Popular clustering algorithms include K-Means, DBSCAN, and Hierarchical Clustering. Association finds relationships between variables, commonly used in market basket analysis (e.g., identifying products often bought together, like "People who buy bread also buy butter"). Apriori and FP-Growth are commonly used association algorithms.
Unsupervised Learning is widely applied in fraud detection, anomaly detection, recommendation systems, and medical imaging. However, since there are no labeled outputs, evaluating the model's accuracy is challenging. Despite these challenges, Unsupervised Learning is crucial for discovering valuable patterns in vast datasets, making it a key approach in data science and AI..
4. Reinforcement Learning
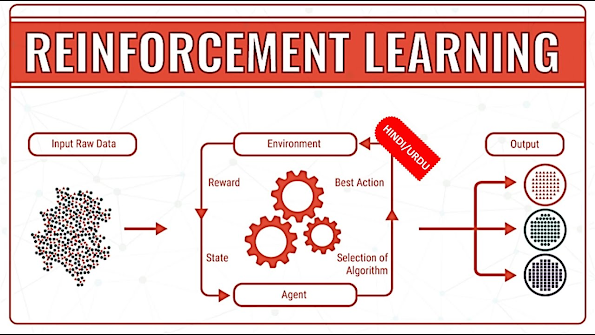
Reinforcement Learning (RL) is a type of Machine Learning where an agent learns to make decisions by interacting with an environment. Unlike Supervised Learning, which relies on labeled data, or Unsupervised Learning, which identifies patterns, RL follows a trial-and-error approach to maximize rewards. The agent takes actions in an environment, receives feedback in the form of rewards or penalties, and continuously improves its decision-making process. This learning method is inspired by human behavior, where individuals learn from past experiences and adjust their actions accordingly.
The key components of RL include the agent (decision-maker), environment (external system), state (current situation), actions (possible choices), rewards (feedback for actions), policy (strategy for decision-making), value function (long-term reward estimation), and Q-learning (technique to find optimal actions). The agent's goal is to develop a policy that maximizes cumulative rewards over time. Popular algorithms used in RL include Q-Learning, Deep Q-Networks (DQN), and Policy Gradient Methods.
Reinforcement Learning is widely used in robotics, gaming (e.g., AlphaGo, Chess AI), self-driving cars, recommendation systems, and automated trading. It enables AI to master complex tasks, such as playing strategic games at a superhuman level or optimizing robotic movements. However, RL has challenges, including high computational costs, long training times, and difficulties in handling unpredictable environments. Despite these challenges, RL continues to revolutionize AI and automation, making machines more adaptive and intelligent in real-world applications.
5. Deep Learning
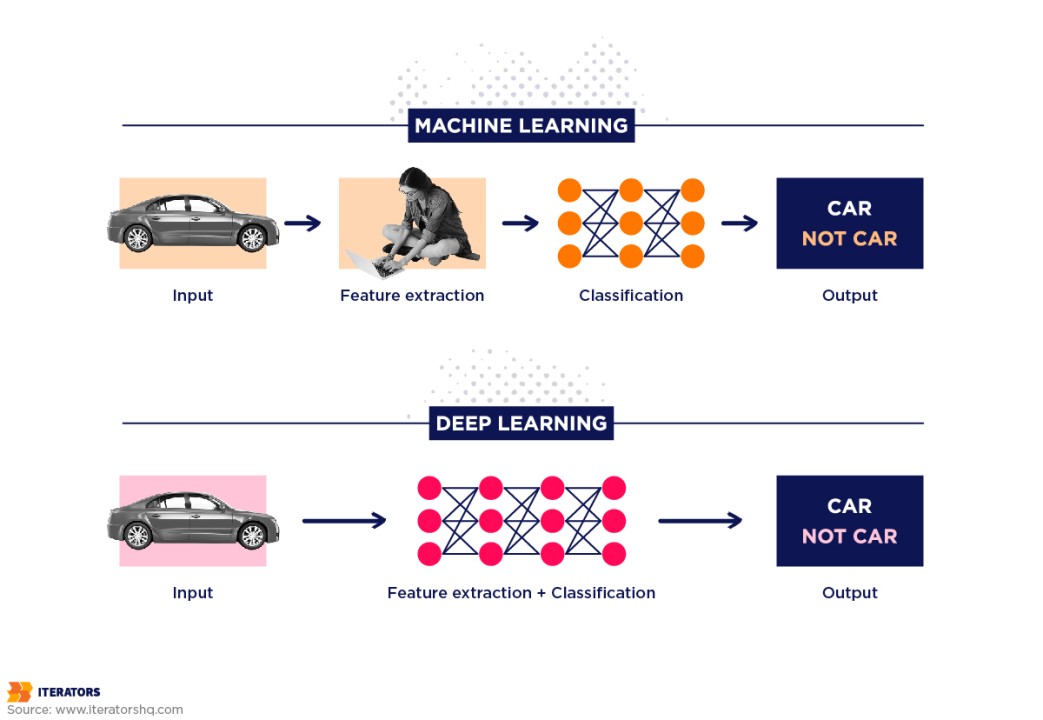
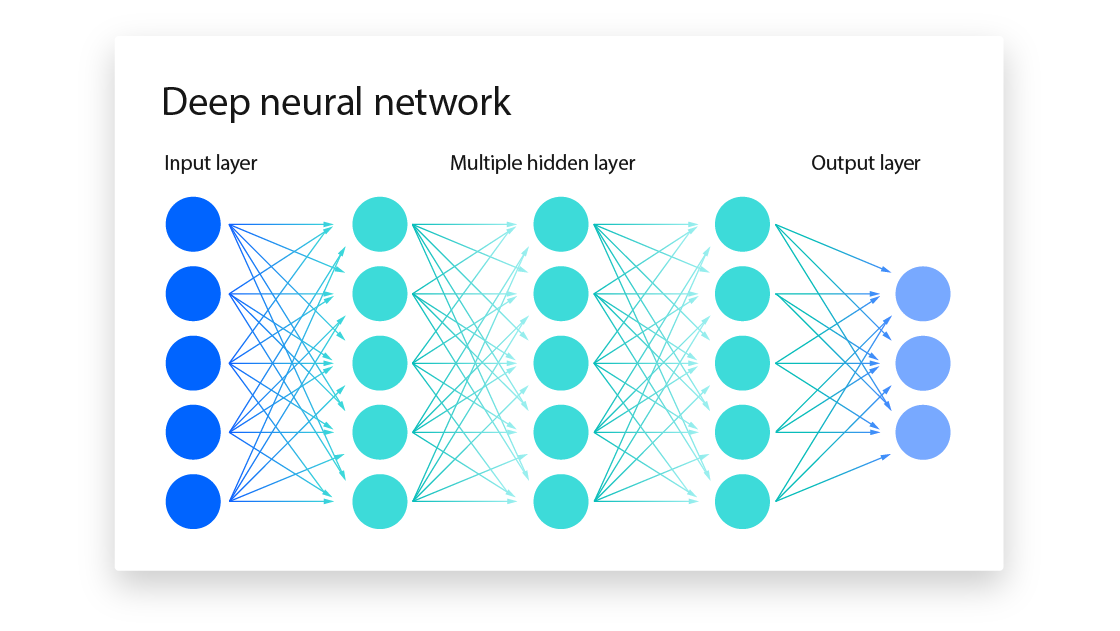
Deep Learning is a subset of Machine Learning that focuses on training artificial neural networks to recognize patterns and make intelligent decisions. Inspired by the human brain, Deep Learning models use multiple layers of interconnected neurons to process vast amounts of data. These models automatically extract features from raw data, reducing the need for manual feature selection. Unlike traditional Machine Learning, which relies on structured data, Deep Learning excels in handling complex and unstructured data like images, audio, and text.
The core of Deep Learning is the Artificial Neural Network (ANN), which consists of input layers, hidden layers, and output layers. The hidden layers perform computations using activation functions like ReLU, Sigmoid, and Softmax. Deep Learning algorithms use techniques like Backpropagation and Gradient Descent to adjust the model's weights and improve accuracy. Popular architectures include Convolutional Neural Networks (CNNs) for image processing, Recurrent Neural Networks (RNNs) for sequential data, and Transformer models (like GPT and BERT) for Natural Language Processing (NLP).
Deep Learning is widely applied in computer vision, speech recognition, medical diagnostics, self-driving cars, and AI assistants like Siri and Alexa. However, it requires large datasets, high computational power (GPUs/TPUs), and careful tuning to avoid overfitting. Despite these challenges, Deep Learning continues to drive advancements in Artificial Intelligence, making machines more capable of performing human-like tasks with high accuracy.
6. Neural Networks
Neural Networks are the foundation of Deep Learning and are designed to mimic the functioning of the human brain. They consist of interconnected layers of artificial neurons that process data and identify patterns. A typical Artificial Neural Network (ANN) has three types of layers: the input layer, which receives raw data; one or more hidden layers, which perform complex calculations; and the output layer, which provides the final prediction or classification. Each neuron in a layer is connected to neurons in the next layer, and these connections have weights that adjust during training to improve accuracy.
Neural Networks use activation functions such as ReLU (Rectified Linear Unit) for hidden layers and Sigmoid or Softmax for output layers to determine neuron activation. They learn through Backpropagation, a process that adjusts weights using Gradient Descent to minimize errors. Popular types of Neural Networks include Convolutional Neural Networks (CNNs) for image recognition, Recurrent Neural Networks (RNNs) for sequential data like speech and text, and Transformer models like GPT for Natural Language Processing (NLP).
Neural Networks are widely used in computer vision, speech recognition, financial predictions, robotics, and autonomous systems. However, they require large datasets, high computational power, and careful tuning to avoid overfitting. Despite these challenges, Neural Networks continue to drive innovations in AI, enabling machines to perform tasks that once required human intelligence.
7. Feature Engineering
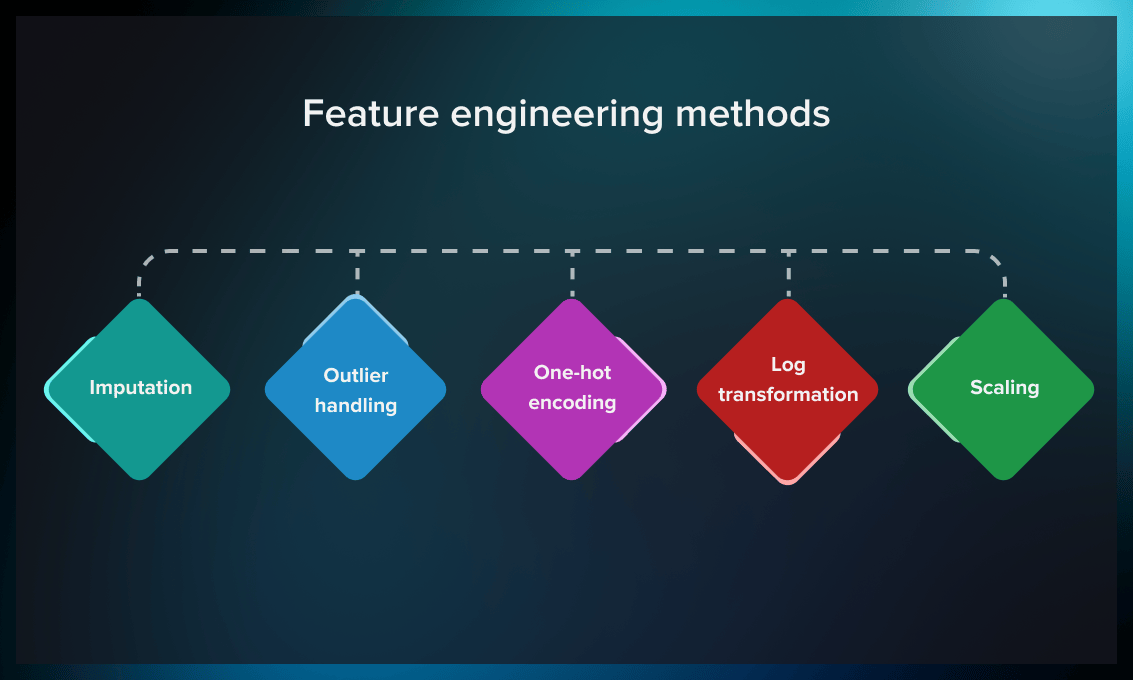
Feature Engineering is a crucial step in Machine Learning where raw data is transformed into meaningful features that improve model performance. Features are the input variables used by machine learning algorithms to make predictions. The goal of Feature Engineering is to create relevant, high-quality features that enhance the model’s ability to identify patterns and relationships in data.
The process involves several techniques, including Feature Selection, Feature Extraction, and Feature Transformation. Feature Selection removes irrelevant or redundant features to reduce complexity and improve efficiency. Feature Extraction creates new informative features, such as converting text into numerical vectors in Natural Language Processing (NLP). Feature Transformation applies techniques like normalization, scaling, encoding categorical variables, and polynomial features to make the data more suitable for the model.
Good Feature Engineering leads to higher accuracy, better generalization, and faster model training. It is widely used in domains like finance, healthcare, image processing, and recommendation systems. Despite its importance, Feature Engineering can be time-consuming and requires domain expertise to create meaningful features. However, with the rise of Deep Learning and Automated Machine Learning (AutoML), some aspects of Feature Engineering are being automated, making the process more efficient.
8. Model Evaluation
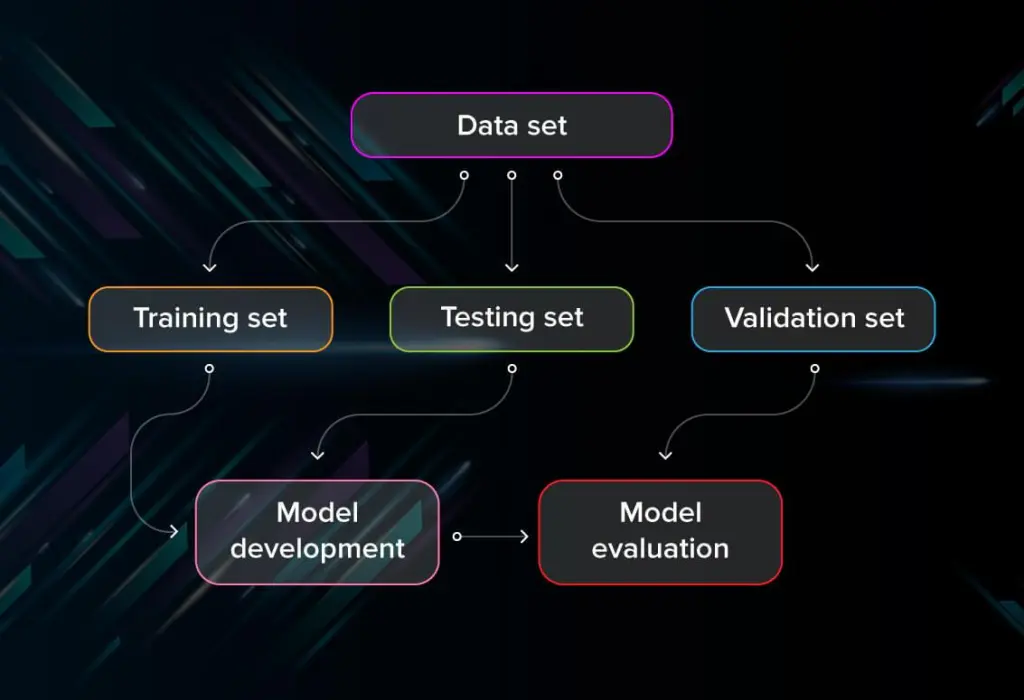
Model Evaluation is a critical step in Machine Learning (ML) that helps determine how well a model performs on unseen data. It ensures that the model makes accurate predictions and generalizes well to new inputs. To evaluate a model effectively, various metrics and techniques are used depending on the type of problem, such as classification, regression, or clustering.
For classification tasks, common evaluation metrics include Accuracy, Precision, Recall, F1-Score, and the ROC-AUC curve. Accuracy measures the percentage of correct predictions, while Precision and Recall evaluate how well the model distinguishes between classes. The F1-Score balances Precision and Recall, and the ROC-AUC curve assesses the model’s ability to differentiate between positive and negative classes.
For regression tasks, evaluation metrics include Mean Absolute Error (MAE), Mean Squared Error (MSE), Root Mean Squared Error (RMSE), and R² score. These metrics measure how close the predicted values are to the actual values. Lower error values indicate better performance.
Other techniques for evaluating models include Cross-Validation, where the dataset is split into multiple parts to test the model’s consistency, and Confusion Matrix, which visualizes the model’s classification performance. Proper Model Evaluation helps detect issues like overfitting and underfitting, ensuring the model performs well in real-world applications.
Comments