Big Data Fundamentals
1. what is Big Data Fundamentals?

Big Data Fundamentalsencompass a set of technologies and methodologies used to manage, analyze, and derive insights from large and complex datasets. One of the primary characteristics of big data is its Volume, referring to the massive amount of data generated daily across industries, such as healthcare, retail, finance, and social media. Traditional databases struggle to handle the sheer quantity of data produced, which is why specialized tools like Hadoop, Spark, and NoSQL databases have been developed to store and process this information. These technologies are capable of distributing data processing tasks across multiple servers or systems, ensuring scalability and faster analysis. The large volume of data often means that companies need to implement effective storage solutions like data lakes and distributed file systems to securely store the data and make it accessible for processing and querying.
Another key aspect of big data is its Variety. Data comes in many forms and can be structured, semi-structured, or unstructured. Structured data, like traditional spreadsheets and databases, is highly organized and can easily be processed by traditional tools. However, a significant portion of big data consists of unstructured or semi-structured data, such as social media posts, emails, images, videos, or sensor data. Handling this variety requires advanced data processing and integration tools that can transform raw data into usable formats. Technologies like natural language processing (NLP) and image recognition are often employed to analyze unstructured data, while platforms like Apache Kafka and ETL (Extract, Transform, Load) tools help organize and structure data for further analysis. Understanding and making sense of this vast array of data types allows businesses to gain a more comprehensive view of their operations, customers, and markets.
The third fundamental characteristic of big data is Velocity, which refers to the speed at which data is generated, processed, and analyzed. In many industries, real-time or near-real-time processing is crucial. For example, financial markets require the processing of thousands of transactions per second, while IoT sensors in manufacturing plants generate continuous streams of data that need to be analyzed instantly to predict equipment failures or optimize production processes. Big data solutions for velocity include real-time streaming technologies like Apache Storm, Apache Flink, and Apache Kafka, which are designed to handle continuous data flows and enable immediate analysis. Organizations use these technologies to gain real-time insights, make faster decisions, and deliver more responsive services to customers. By addressing the challenges of volume, variety, and velocity, big data technologies empower organizations to extract valuable insights from complex datasets, fostering innovation and better decision-making across various sectors.
2.Structured vs Unstructured Data
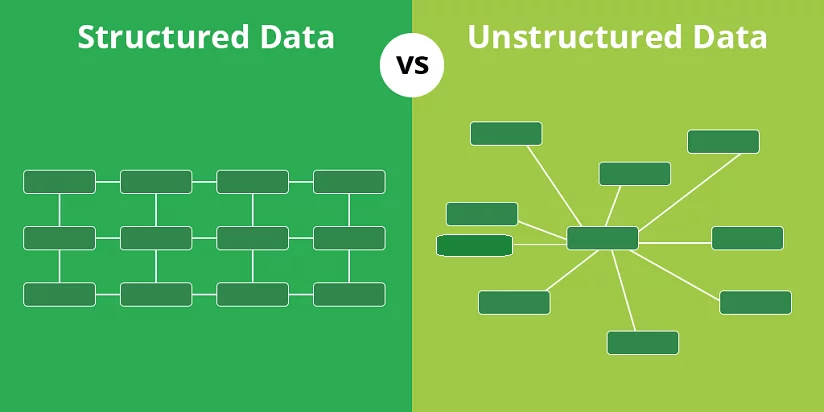
Structured vs Unstructured Data
Structured Data: This type of data is highly organized and easily searchable because it follows a predefined model or schema. Structured data is typically stored in relational databases (RDBMS) like MySQL, Oracle, or SQL Server, where it exists in rows and columns, making it easy to process, query, and analyze using structured query language (SQL). Examples of structured data include customer names, addresses, phone numbers, sales transactions, and inventory lists. Because of its rigid format, structured data is ideal for transactional systems, data warehouses, and situations where quick, reliable analysis is required. Its organization allows for fast querying, filtering, and aggregating, enabling businesses to make data-driven decisions efficiently.
Unstructured Data: Unlike structured data, unstructured data does not follow a predefined model or organization, which makes it more difficult to manage, analyze, and store. It includes data such as text documents, emails, social media posts, images, videos, audio recordings, and sensor data, all of which do not have a consistent format. Unstructured data accounts for a large portion of the data generated in the modern world, and its volume is rapidly increasing. Analyzing unstructured data often requires advanced techniques like natural language processing (NLP) for text, image recognition for visual data, and speech recognition for audio files. To process and store unstructured data, technologies like NoSQL databases, data lakes, and cloud storage are used.
Comparison: The key difference between structured and unstructured data lies in their organization and analysis complexity. Structured data is highly organized, making it easier to analyze using traditional tools, while unstructured data requires advanced techniques and technologies to extract useful information. Structured data is best suited for operations that demand high accuracy, quick querying, and straightforward analysis, such as financial transactions and customer records. On the other hand, unstructured data provides richer, more nuanced insights, especially in areas like customer sentiment analysis, media content, and IoT data analysis. Organizations today are increasingly looking to harness the power of both types of data by integrating structured and unstructured datasets to create more comprehensive, insightful analyses.
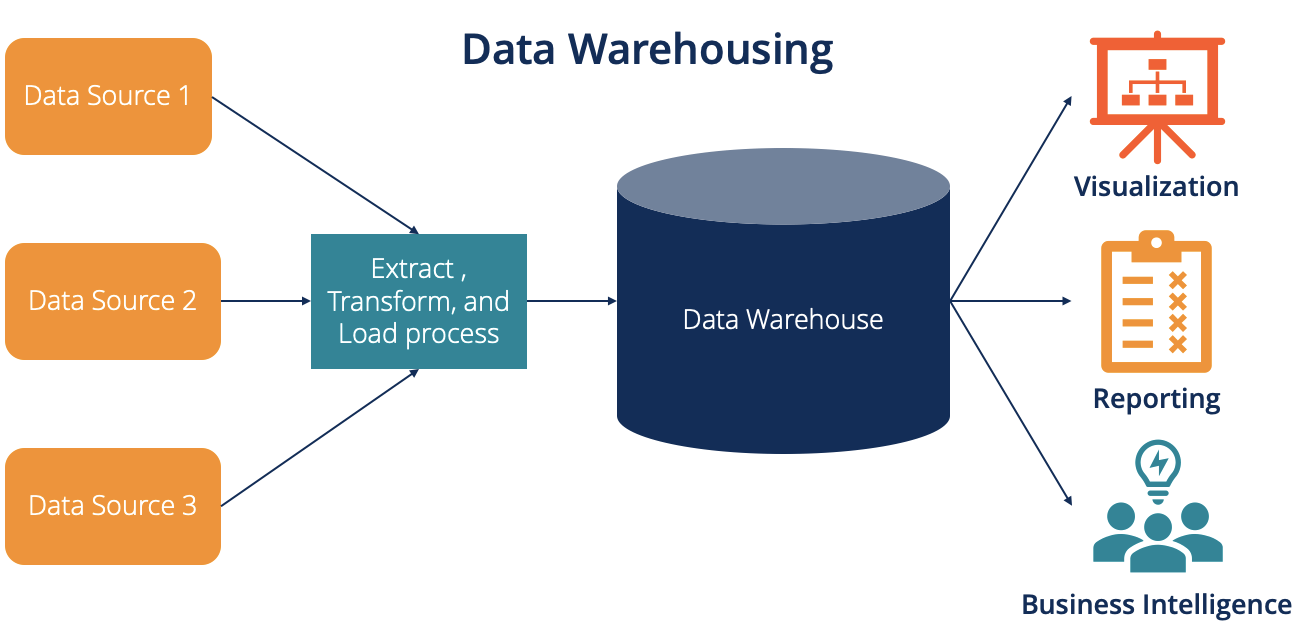
3.Data Warehousing
Data Warehousing
refers to the process of collecting, storing, and managing large volumes of data from various sources in a centralized, structured environment. This data is then made available for analysis, reporting, and decision-making. A data warehouse is specifically designed to handle complex queries and facilitate business intelligence (BI) processes. It allows organizations to aggregate data from disparate systems and provide a unified view, making it easier to derive actionable insights and improve decision-making.
Data warehousing systems store historical data in an optimized format that is specifically designed for query performance and reporting. Unlike operational databases, which are optimized for real-time transactions, a data warehouse is designed for analytical processing, often referred to as Online Analytical Processing (OLAP). This is why data warehouses are typically used in environments that require complex data analysis, such as business intelligence, forecasting, and trend analysis. The data is extracted from various sources using ETL (Extract, Transform, Load) processes—extracting data from operational databases or external sources, transforming it into a useful format, and loading it into the data warehouse.
Data warehouses support critical decision-making processes by ensuring that data is accurate, accessible, and available for querying at scale. They enable businesses to analyze trends, understand customer behavior, optimize operations, and make strategic decisions based on large volumes of data.
Data Warehousing
refers to the process of collecting, storing, and managing large volumes of data from various sources in a centralized, structured environment. This data is then made available for analysis, reporting, and decision-making. A data warehouse is specifically designed to handle complex queries and facilitate business intelligence (BI) processes. It allows organizations to aggregate data from disparate systems and provide a unified view, making it easier to derive actionable insights and improve decision-making.
Data warehousing systems store historical data in an optimized format that is specifically designed for query performance and reporting. Unlike operational databases, which are optimized for real-time transactions, a data warehouse is designed for analytical processing, often referred to as Online Analytical Processing (OLAP). This is why data warehouses are typically used in environments that require complex data analysis, such as business intelligence, forecasting, and trend analysis. The data is extracted from various sources using ETL (Extract, Transform, Load) processes—extracting data from operational databases or external sources, transforming it into a useful format, and loading it into the data warehouse.
Data warehouses support critical decision-making processes by ensuring that data is accurate, accessible, and available for querying at scale. They enable businesses to analyze trends, understand customer behavior, optimize operations, and make strategic decisions based on large volumes of data.
4.Data Mining Techniques
Data Mining Techniques
refers to the process of discovering patterns, correlations, and useful information from large datasets using statistical, mathematical, and computational methods. The techniques used in data mining allow businesses and organizations to analyze vast amounts of raw data and turn it into meaningful insights that can drive decision-making, predict trends, and solve problems. The primary goal of data mining is to extract knowledge from data, uncover hidden patterns, and identify relationships that are not immediately apparent.
One of the most common data mining techniques is Classification, which is used to categorize data into predefined classes or groups based on input features. In classification, historical data with known outcomes is used to train models, such as decision trees, support vector machines (SVM), and k-nearest neighbors (KNN). Once trained, the model can be used to classify new, unseen data into categories. This technique is widely used in applications such as spam detection, credit scoring, and medical diagnosis. Another significant technique is Clustering, which groups similar data points together based on their attributes without prior labels. Clustering algorithms, such as k-means and hierarchical clustering, help identify inherent structures within the data, making it valuable for market segmentation, customer behavior analysis, and anomaly detection.
Another important technique is Association Rule Learning, which is used to discover interesting relationships between variables in large datasets. The most popular example of this is the Apriori algorithm, which is widely used in market basket analysis to find associations between products that are frequently bought together. For example, if customers often buy milk and bread together, this relationship can be identified through association rule learning. Regression analysis is another widely used data mining technique, often used for predicting continuous values based on historical data. It helps in estimating real-world values such as house prices, sales forecasting, or stock prices based on past trends and variables. These techniques collectively contribute to the discovery of insights that can enhance decision-making, customer targeting, and operational efficiency across industries.

5.Data Governance & Compliance
Data Governance & Compliance
refers to the set of processes, policies, and standards that ensure the proper management, security, availability, and quality of data within an organization. It involves the implementation of rules and guidelines for how data is collected, stored, accessed, and utilized. The main goal of data governance is to ensure that data is accurate, consistent, secure, and used responsibly across the organization. Effective data governance ensures that data is treated as a valuable asset and is managed in a way that supports compliance with laws, regulations, and industry standards, while also meeting business needs
One of the key components of data governance is data quality management, which focuses on maintaining the accuracy, completeness, consistency, and timeliness of data. Data governance also involves defining the roles and responsibilities related to data within an organization, such as data stewards, data owners, and data custodians. These roles are crucial for overseeing the governance processes and ensuring that data is properly managed throughout its lifecycle. Another important aspect is data security, where policies and technologies are implemented to protect sensitive information from unauthorized access, loss, or corruption. This includes setting up access controls, encryption, and regular audits to monitor the security status of data systems.
Data Compliance refers to the adherence to laws, regulations, and industry standards that govern the collection, processing, and storage of data. Compliance is essential for organizations to avoid legal risks, protect consumer privacy, and maintain trust. Examples of data compliance frameworks include the General Data Protection Regulation (GDPR), which sets guidelines for data protection and privacy for individuals in the European Union, and the Health Insurance Portability and Accountability Act (HIPAA), which governs the privacy and security of healthcare data in the United States. Organizations must ensure that they follow these and other relevant regulations to safeguard personal data, ensure transparency, and enable individuals to have control over their data. Non-compliance can lead to significant financial penalties and damage to the organization’s reputation.

6.Big Data Storage Solutions
Big Data Storage Solutions
are designed to handle the massive volume, velocity, and variety of data generated by modern businesses and organizations. These solutions provide the infrastructure needed to store, manage, and retrieve large datasets, ensuring that they are accessible, scalable, and efficient. Given the vast amounts of data generated across multiple sources such as sensors, social media, transactional systems, and IoT devices, traditional storage solutions are often inadequate for big data applications. As a result, specialized storage systems are necessary to support data-intensive tasks, such as analytics, machine learning, and real-time processing.
One of the most common big data storage solutions is Distributed File Systems (DFS), which break down large datasets into smaller pieces and distribute them across multiple machines or nodes. The most widely used DFS is Hadoop Distributed File System (HDFS), which is designed for high-throughput access to large datasets and provides fault tolerance through data replication. HDFS allows businesses to store petabytes of data across commodity hardware, ensuring both reliability and scalability. Other distributed file systems include Google File System (GFS) and Ceph, which offer similar functionality for handling large-scale data storage needs. Distributed systems ensure that even as data grows, the storage infrastructure can scale horizontally by adding more nodes to the cluster.
Another major solution for big data storage is Cloud Storage, which offers highly scalable and cost-effective storage options for businesses dealing with large volumes of data. Cloud providers such as Amazon Web Services (AWS), Microsoft Azure, and Google Cloud Platform (GCP) offer storage services like Amazon S3, Azure Blob Storage, and Google Cloud Storage, which provide virtually unlimited storage capacity and can scale with the demands of big data workloads. Cloud storage offers additional benefits such as redundancy, ease of access, and flexibility in terms of pricing and data retrieval speed. These platforms often integrate with data processing frameworks like Hadoop and Spark, enabling seamless data management and analysis across distributed computing environments.

7.Cloud-based Data Processing
Cloud-based Data Processing
refers to the use of cloud computing platforms and services to process, manage, and analyze large datasets. With cloud-based solutions, businesses can offload the heavy lifting of data processing to scalable, on-demand resources, eliminating the need for expensive on-premise infrastructure. This approach allows companies to access powerful computing resources without the upfront investment or maintenance costs typically associated with traditional data centers. Cloud data processing provides the flexibility to scale computing power and storage capacity based on the specific needs of the organization, making it ideal for data-intensive applications such as big data analytics, machine learning, and real-time data processing.
One of the key advantages of cloud-based data processing is scalability. Cloud platforms such as Amazon Web Services (AWS), Google Cloud Platform (GCP), and Microsoft Azure offer services that allow businesses to scale their data processing resources up or down based on workload demands. For instance, services like Amazon EC2 or Google Compute Engine enable businesses to launch virtual machines with varying computational power to process large datasets in parallel, making it easier to handle data spikes or increased demand. Cloud data processing solutions also include managed big data services like AWS EMR (Elastic MapReduce), Google BigQuery, and Azure HDInsight, which provide fully managed platforms for running big data frameworks like Hadoop and Spark. These platforms allow businesses to focus on their data analysis without worrying about infrastructure management, as cloud providers handle the scaling, updates, and maintenance of the processing environment.
Another benefit of cloud-based data processing is the ability to leverage real-time data processing for fast insights. Cloud services enable organizations to stream and process data in real time using tools like Apache Kafka, Amazon Kinesis, and Google Cloud Dataflow. This is particularly valuable for applications that require immediate analysis and action, such as fraud detection, recommendation engines, or IoT applications. By processing data streams as they are generated, organizations can gain insights almost instantaneously, allowing for faster decision-making and more responsive services. Additionally, cloud-based data processing platforms are designed to integrate seamlessly with other cloud services like data storage, machine learning, and analytics, creating a comprehensive ecosystem for data management and analysis.
8.Role of AI in Big Data
Role of AI in Big Data is pivotal as AI technologies enhance the ability to process, analyze, and extract valuable insights from vast amounts of data. Big Data refers to datasets that are too large, complex, or dynamic for traditional data-processing tools to handle efficiently. AI, with its advanced algorithms and machine learning models, can handle the complexity of big data by automating data analysis, identifying patterns, and making predictions. AI's role in big data spans several areas, including data processing, data mining, predictive analytics, and decision-making, allowing businesses to unlock actionable insights and make more informed decisions.
One of the key ways AI contributes to big data is through data analysis and automation. AI-powered algorithms, such as machine learning and deep learning, can sift through enormous datasets to identify patterns, trends, and anomalies that might go unnoticed by human analysts. Traditional methods of data processing can struggle to handle the velocity and variety of data streams, especially in real-time applications like social media analysis, sensor data, and e-commerce transactions. AI, on the other hand, can process this data rapidly and accurately, offering more reliable insights. For example, Natural Language Processing (NLP) models allow AI to analyze and understand unstructured data, like text from emails, social media posts, or customer reviews, which is often the most abundant form of big data.
Another critical area where AI plays a significant role in big data is predictive analytics. By leveraging machine learning algorithms, AI can make accurate predictions based on historical data, trends, and patterns. For instance, in industries like healthcare, AI can analyze vast amounts of patient data to predict future health conditions or suggest personalized treatment options. In e-commerce, AI can analyze customer purchasing patterns to recommend products. The ability to predict future events or behaviors is incredibly valuable for businesses looking to improve customer experience, optimize supply chains, or reduce risks. AI can also enhance forecasting models, helping businesses better anticipate market changes and consumer demand, which is crucial for long-term strategic planning.

Role of AI in Big Data is pivotal as AI technologies enhance the ability to process, analyze, and extract valuable insights from vast amounts of data. Big Data refers to datasets that are too large, complex, or dynamic for traditional data-processing tools to handle efficiently. AI, with its advanced algorithms and machine learning models, can handle the complexity of big data by automating data analysis, identifying patterns, and making predictions. AI's role in big data spans several areas, including data processing, data mining, predictive analytics, and decision-making, allowing businesses to unlock actionable insights and make more informed decisions.
One of the key ways AI contributes to big data is through data analysis and automation. AI-powered algorithms, such as machine learning and deep learning, can sift through enormous datasets to identify patterns, trends, and anomalies that might go unnoticed by human analysts. Traditional methods of data processing can struggle to handle the velocity and variety of data streams, especially in real-time applications like social media analysis, sensor data, and e-commerce transactions. AI, on the other hand, can process this data rapidly and accurately, offering more reliable insights. For example, Natural Language Processing (NLP) models allow AI to analyze and understand unstructured data, like text from emails, social media posts, or customer reviews, which is often the most abundant form of big data.
Another critical area where AI plays a significant role in big data is predictive analytics. By leveraging machine learning algorithms, AI can make accurate predictions based on historical data, trends, and patterns. For instance, in industries like healthcare, AI can analyze vast amounts of patient data to predict future health conditions or suggest personalized treatment options. In e-commerce, AI can analyze customer purchasing patterns to recommend products. The ability to predict future events or behaviors is incredibly valuable for businesses looking to improve customer experience, optimize supply chains, or reduce risks. AI can also enhance forecasting models, helping businesses better anticipate market changes and consumer demand, which is crucial for long-term strategic planning.
Comments